
21.7: Controlling for Confounding Variables
- Page ID
- 13734
7.1 The nature of confounding variables
A risk factor for the disease under study that is differentially distributed among the groups receiving different interventions in which the disease incidence is being compared is called a confounding factor. Unless the trial is very small, confounding factors are not likely to bias the comparisons between intervention and control groups in randomized trials, as the process of randomization ensures that any such factors, whether known or unknown, will be equally distributed in the different groups (apart from random variation). In studies in which those in the different groups have not been allocated at random, the control of confounding factors is a critical component in the analysis. For example, consider a comparative study of TB incidence in persons who received BCG in a routine vaccination programme and those who were not vaccinated. BCG coverage is often higher in urban areas and, independently of any effect of BCG, those living in urban areas also tend to have a higher incidence of TB because of overcrowding and other environmental factors. In this instance, residential status (rural/urban) could be a confounding factor, and, if it is not taken into account in the analyses, any protective effect of BCG against TB might be underestimated. Consider the hypothetical situation depicted in Table 21.8, which shows the incidence of TB over a 10-year period in BCG-vaccinated and unvaccinated individuals in urban and rural areas.
BCG coverage is appreciably higher in the urban population (80%) than in the rural population (50%). Also, in unvaccinated persons, the incidence of TB is higher in the urban population (20 per thousand over 10 years) than in the rural population (10 per thousand). In consequence, although BCG vaccine efficacy is 50% in both urban and rural areas, the estimate obtained from a comparative study, in which the place of residence is ignored, is only 41%. This difference is due to the confounding effect of the place of residence on the estimate of efficacy (the place of residence being related to both the disease incidence and, independently, to the prevalence of vaccination).
7.2 Adjusting for confounding variables
A powerful way of removing the effect of a confounding variable is to restrict comparative analyses to individuals who share a common level of the confounding variable and then to combine the results across the different levels in such a way so as to avoid bias. Thus, in the example in Table 21.8, if the vaccine efficacy was first estimated separately for rural and urban dwellers, and then the two estimates were to be combined, the estimate of efficacy obtained (50%) would be free of the confounding bias of the place of residence. In general, to control for confounding, the study population is divided into a number of strata. Within each stratum, individuals share a common level of the confounding variable. Estimates of risk, rate or mean differences, or ratios are made within each stratum, and the resulting estimates are then pooled in some way across strata, in order to obtain an overall measure of the effect which is free of any confounding due to the variable on which the stratification was made. Such stratification may be carried out on several confounding variables simultaneously (for example, age and sex).
If it is known, when a study is planned, that it will be necessary to allow for confounding variables in the analysis, it is desirable to give consideration to this at the design stage, both in terms of the information which must be collected and because it will require an increase in the required sample sizes (to achieve the desired statistical power, see Chapter 5). Usually, the necessary increase in sample size to allow for confounding variables is not great (for example, less than 20%), and often the information needed for these sample size calculations is not available before the study starts anyway. Formal methods for calculating sample sizes, allowing for adjustment for confounding variables, are given in Breslow and Day (1987).
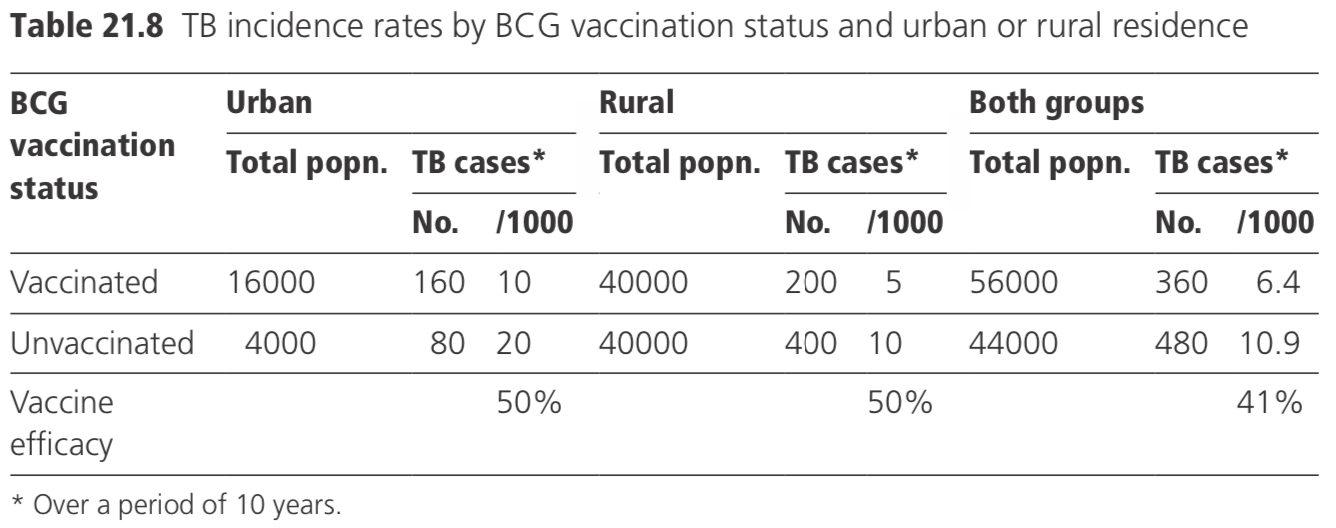
7.3 Adjusting risks
7.3.1 Overall test of significance
After stratifying on the basis of the confounding variable(s), the analysis is conducted one stratum at a time, and then the results are pooled. In the ith stratum, the data may be depicted, as shown in Table 21.9.
To test the hypothesis that the relative risk is 1 in all strata or equivalently that the risk difference is zero in each stratum, a generalization of the method given in Section 4.2 may be used. The statistical test is known as the Mantel–Haenszel test.

In the i th stratum:
\[
\text { Expected value of } a_{\mathrm{i}}=E\left(a_{\mathrm{i}}\right)=m_{1 \mathrm{i}} n_{1 \mathrm{i}} / N_{\mathrm{i}}
\]
\[
\text { Variance of } a_{\mathrm{i}}=V\left(a_{\mathrm{i}}\right)=n_{1 \mathrm{i}} n_{2 \mathrm{i}} m_{1 \mathrm{i}} m_{2 \mathrm{i}} /\left[N_{\mathrm{i}}^{2}\left(N_{\mathrm{i}}-1\right)\right]
\]
An overall test of the null hypothesis that the relative risk is unity is given by calculating χ2 =(Σai −ΣE(ai )−0.5)2 /ΣV(ai), where the summation is over all strata, which may be tested for statistical significance using tables of the chi-squared distribution with one df.
The calculations are illustrated in Table 21.10, with data on disease incidence rates in vaccinated and unvaccinated individuals in three areas—urban, semi-urban, and rural.
\[\Sigma a_{i}=530 ; \Sigma E\left(a_{i}\right)=738 ; \Sigma V\left(a_{i}\right)=284.21\]
Thus:
$$x^{2}=(|530-738|-0.5)^{2} / 284.21=151.49\]
Thus, there is very strong evidence against the null hypothesis, as p < 0.000001 (from tables of the chi-squared distribution).
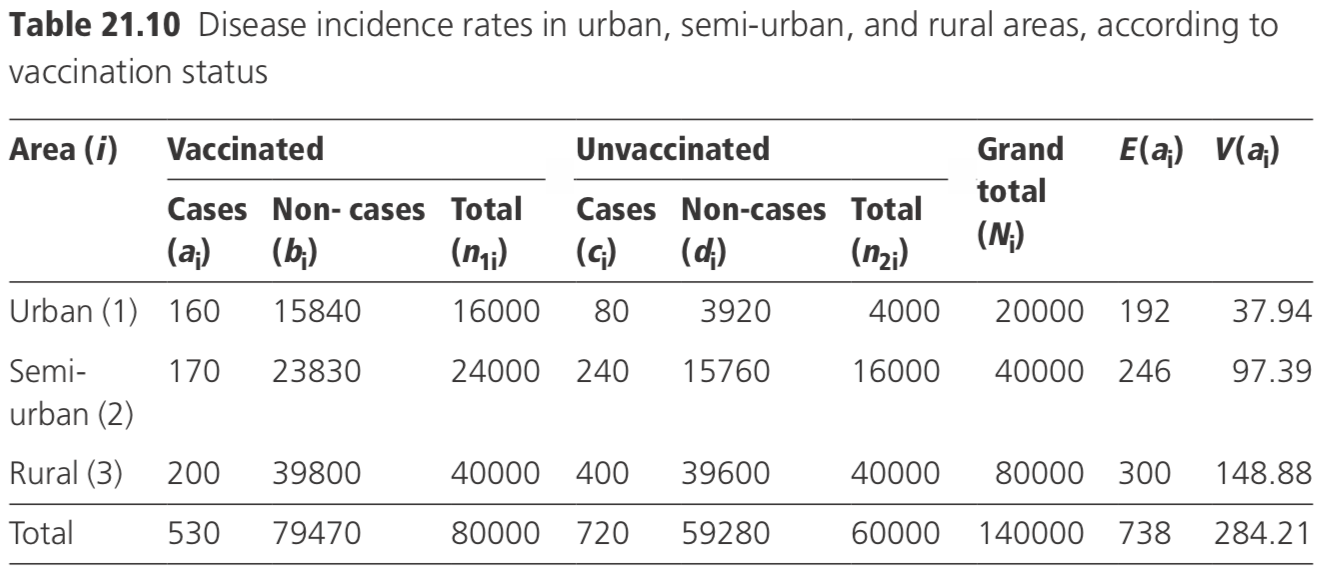
7.3.2 Pooled estimate of risk difference
If it is considered that the risk difference (rather than the risk ratio) is likely to be constant across different strata, a pooled estimate of the common risk difference may be required. This is obtained by taking a weighted average of the risk differences in each stratum, weighting each by the inverse of its variance (as this may be shown to give the ‘best’ estimate of the common risk difference).
In the i th stratum, the risk difference is:
\[
d_{\mathrm{i}}=p_{\mathrm{li}}-p_{2 \mathrm{i}}=\left(a_{\mathrm{i}} / n_{1 \mathrm{i}}\right)-\left(c_{\mathrm{i}} / n_{2 \mathrm{i}}\right)
\]
and the variance of the risk difference is:
\[
V\left(d_{\mathrm{i}}\right)=\left\{p_{\mathrm{i}}\left(1-p_{\mathrm{i}}\right)\left[\left(1 / n_{\mathrm{li}}\right)+\left(1 / n_{2 \mathrm{i}}\right)\right]\right\}
\]
(as given also in Section 4.2), where:
\[
p_{\mathrm{i}}=\left[n_{1 \mathrm{i}} p_{1 \mathrm{i}}+n_{2 \mathrm{i}} p_{2 \mathrm{i}}\right] /\left(n_{1 \mathrm{i}}+n_{2 \mathrm{i}}\right)=\left(a_{\mathrm{i}}+c_{\mathrm{i}}\right) /\left(n_{1 \mathrm{i}}+n_{2 \mathrm{i}}\right)
\]
Now, let wi =1/V(di ).
The pooled estimate of the common risk difference is given by d = Σwidi /Σwi. For the data in the example given in Table 21.10, the computations for the common risk difference are shown in Table 21.11.
Pooled estimate of the common risk difference d =Σwidi /Σwi =−0.0083.
7.3.3 Pooled estimate of risk ratio
A pooled estimate of the common risk ratio R across strata may be obtained, using the following formulae.
In the i th stratum, the risk ratio is given by:
\[
R_{\mathrm{i}}=\left(a_{\mathrm{i}} / n_{1 \mathrm{i}}\right) /\left(c_{\mathrm{i}} / n_{2 \mathrm{i}}\right)=a_{\mathrm{i}} n_{2 \mathrm{i}} /\left(c_{\mathrm{i}} n_{1 \mathrm{i}}\right)
\]
A pooled estimate across all strata is given by:
\[
R=\Sigma\left(a_{1} n_{2 i} / N_{i}\right) / \Sigma\left(c_{i} n_{1 i} / N_{i}\right)
\]
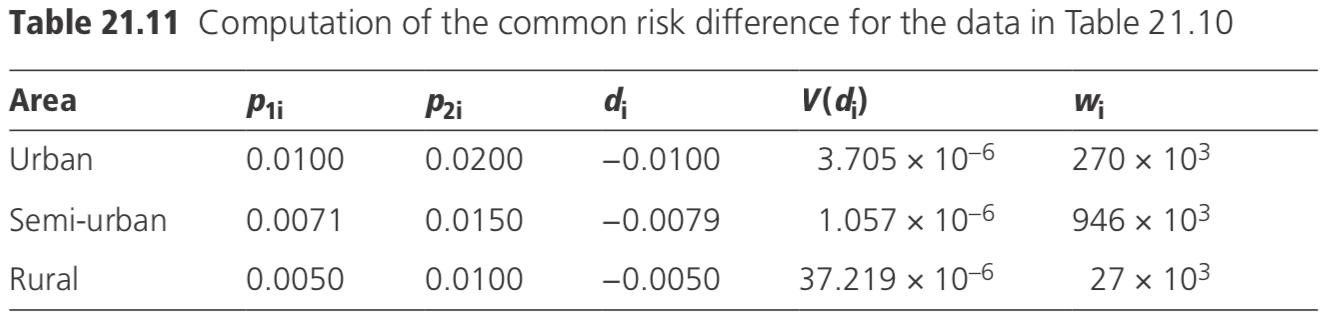
Thus, for the example in Table 21.10:
\[\begin{align} R = & \{ [(160)(4000)/20 000]+ (170)(16 000)/40 000] + [(200)(40 000)/80 000]\} \\& / \{ [(80)(16 000)/20 000]+ [(240)(24 000)/40 000 + [(400)(40 000)/80 000] \} \\ =& 200/408 \\ =& 0.49.\end{align}\]
7.3.4 Confidence intervals
The easiest way of obtaining CIs on the estimates of the common risk difference or the common risk ratio is to use the ‘test-based’ method (Miettinen, 1976).
The approximate 95% CI on the risk difference is given by:
\[
d\left(1 \pm 1.96 / \sqrt{x}^{2}\right)
\]
Thus, in the example in Tables 21.10 and 21.11, the confidence limits are:
\[
-0.0083(1+1.96 / \sqrt{151.49})=-0.0096 \text { to }-0.0070
\]
The 95% CI on the logarithm of the relative risk is given by:
\[
\log _{e} R\left(1 \pm 1.96 / \sqrt{\chi}^{2}\right)
\]
In the example, the confidence limits are:
\[
\log _{e}(0.49)(1 \pm 1.96 / \sqrt{151.49})=-0.8269 \text { to }-0.5998
\]
And thus the confidence limits on the relative risk are 0.44 to 0.55.
7.4 Adjusting rates
The computations for adjusting rates are very similar to those for adjusting risks and involve only some changes to the formulae given in Section 7.3.
Suppose the results observed in the ith stratum are as shown in Table 21.12.
7.4.1 Overall test of significance
In the i th stratum, e1i is the number of individuals who developed disease in group 1.
\[
\text { Expected value of } e_{1 \mathrm{i}}=E\left(e_{1 \mathrm{i}}\right)=e_{\mathrm{i}} y_{1 \mathrm{i}} / y_{\mathrm{i}}
\]
\[
\text { Variance of } e_{1 \mathrm{i}}=V\left(e_{1 \mathrm{i}}\right)=e_{\mathrm{i}} y_{1 \mathrm{i}} y_{2 \mathrm{i}} / y_{\mathrm{i}}^{2}
\]
An overall test of significance (that the common rate ratio is unity or the common rate difference is zero) is given by:
\[
\chi^{2}=\left(\left|\Sigma e_{1 \mathrm{i}}-\Sigma E\left(e_{\mathrm{li}}\right)\right|-0.5\right)^{2} / \Sigma V\left(e_{\mathrm{li}}\right)
\]
where the summation is over all strata.
The value calculated should be looked up in tables of the chi-squared distribution with one df.
7.4.2 Pooled estimate of rate difference
In the i th stratum, the rate difference is:
\[
d_{i}=r_{1 i}-r_{2 i}=\left(e_{i i} / y_{1 i}\right)-\left(e_{2 i} / y_{2 i}\right)
\]
Its estimated variance is:
\[
V\left(d_{i}\right)=\left(r_{1 i} / y_{1 i}+r_{2 i} / y_{2 i}\right)
\]
Let \(w_{\mathrm{i}}=1 / V\left(d_{\mathrm{i}}\right)\) then the estimate of the common rate difference across all strata is given by:
\[d=\sum w_{i} d_{i} / \sum w_{i}\]
7.4.3 Pooled estimate of rate ratio
In the ith stratum, the rate ratio is:
\[
R_{\mathrm{i}}=r_{1 \mathrm{i}} / r_{2 \mathrm{i}}=\left(e_{\mathrm{ii}} / y_{1 \mathrm{i}}\right) /\left(e_{2 \mathrm{i}} / y_{2 \mathrm{i}}\right)=e_{1 \mathrm{i}} y_{2 \mathrm{i}} /\left(e_{2 \mathrm{i}} y_{1 \mathrm{i}}\right)
\]
A pooled estimate of the common rate ratio is given by:
\[
R=\Sigma\left(e_{1 i} y_{2 i} / y_{i}\right) / \Sigma\left(e_{2 i} y_{1 i} / y_{i}\right)
\]
7.4.4 Confidence intervals
The 95% CI on the common rate difference is given by:
\[
d\left(1 \pm 1.96 / \sqrt{\chi^{2}}\right)
\]
The 95% CI on the logarithm of the common rate ratio is given by:
\[
\log _{e} R\left(1 \pm 1.96 / \sqrt{\chi}^{2}\right)
\]
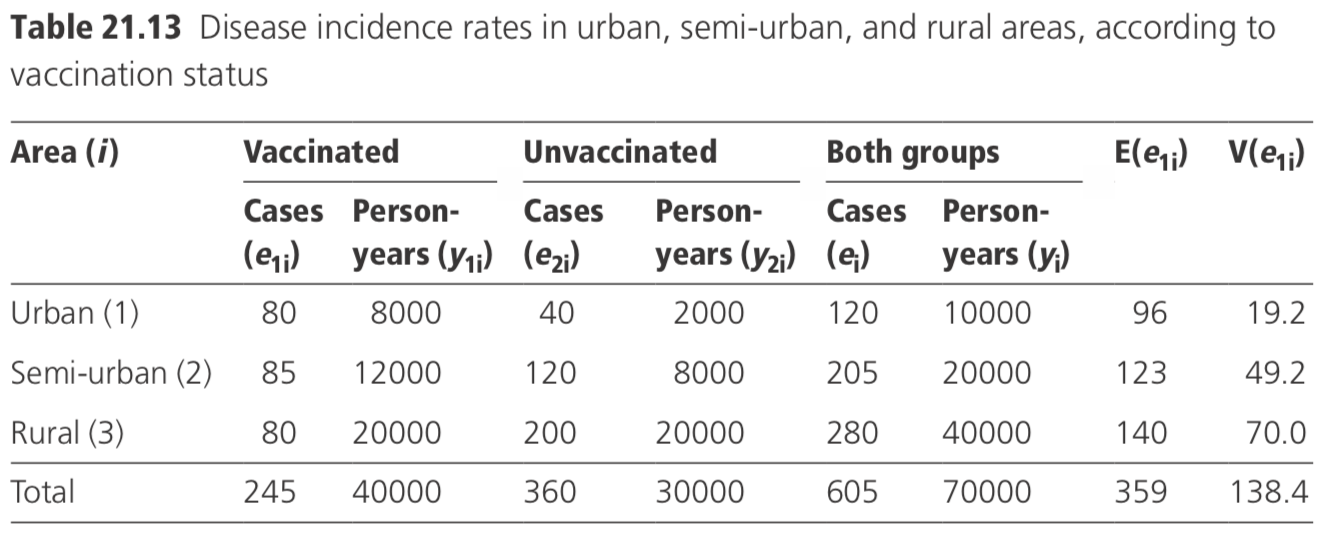
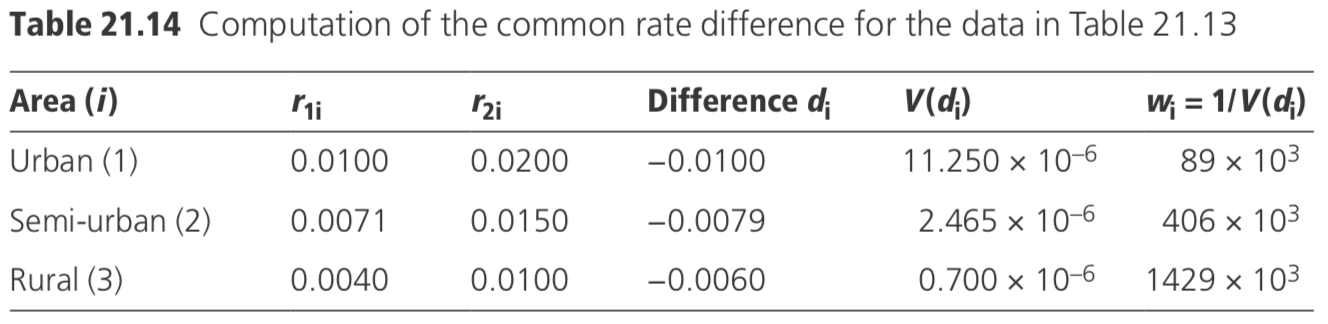
Example: In Table 21.13, the numerical computations are illustrated, as before, with data on the disease incidence in vaccinated and unvaccinated individuals in three areas: urban, semi-urban, and rural.
Overall test of significance:
\[
\chi^{2}=\left(\left|\Sigma e_{1 \mathrm{i}}-\Sigma E\left(e_{1 \mathrm{i}}\right)\right|-0.5\right)^{2} / \Sigma V\left(e_{\mathrm{li}}\right)
\]
\[
=(|245-359|-0.5)^{2} / 138.40=93.08(\mathrm{p}<0.000001)
\]
The estimation of the common rate difference is shown in Table 21.14.
\[
d=\sum w_{i} d_{i} / \sum w_{i}=-0.0066
\]
The 95% CI on the common rate difference is:
\[
d\left(1 \pm 1.96 / \sqrt{\chi}^{2}\right)=-0.0066(1 \pm 1.96 / \sqrt{93.08})
\]
\[
=-0.0079 \text { to }-0.0053
\]
The estimate of the common rate ratio is:
\[\begin{align}R&=Σ(e_{1i}y_{2i}/y_i)/Σ(e_{2i}y_{1i}y_i)\\ &=\{[(80)(2000)/10 000]+[(85)(8000)/20 000]+[(80)(20 000)/40 000]\}/\{[(40)(8000)/10 000]+[(120)(12 000)/20 000]+ [(200)(20 000)/40 000]\}\\&=90/204 \\& =0.44. \end{align}\]
| Area (i) | Vaccinated | Unvaccinated | Both groups | E(e1i) | V(e1i) | |||
|---|---|---|---|---|---|---|---|---|
| Cases (e1i) | Person-years (y1i) | Cases (e2i) | Person-years (y2i) | Cases (ei) | Person-years (yi) | |||
| Urban (1) | 80 | 8000 | 40 | 2000 | 120 | 10000 | 96 | 19.2 |
| Semi-urban (2) | 85 | 12000 | 120 | 8000 | 205 | 20000 | 123 | 49.2 |
| Rural (3) | 80 | 20000 | 200 | 20000 | 280 | 40000 | 140 | 70.0 |
| Total | 245 | 40000 | 360 | 30000 | 605 | 70000 | 359 | 138.4 |
The 95% confidence limits on the logarithm of the common rate ratio is:
\[
\log _{e} R\left(1+1.96 / \sqrt{x^{2}}\right)=\log _{e}(0.44)(1+1.96 / \sqrt{93.08})=-0.988 \text { to }-0.654
\]
Taking the anti-logarithm, the 95% confidence limits on the common rate ratio are 0.37 to 0.52.
7.5 Adjusting means
If the outcome variable is a quantitative measure, other than a risk or rate, adjustment for the effects of a confounding variable involves performing a stratified t-test.
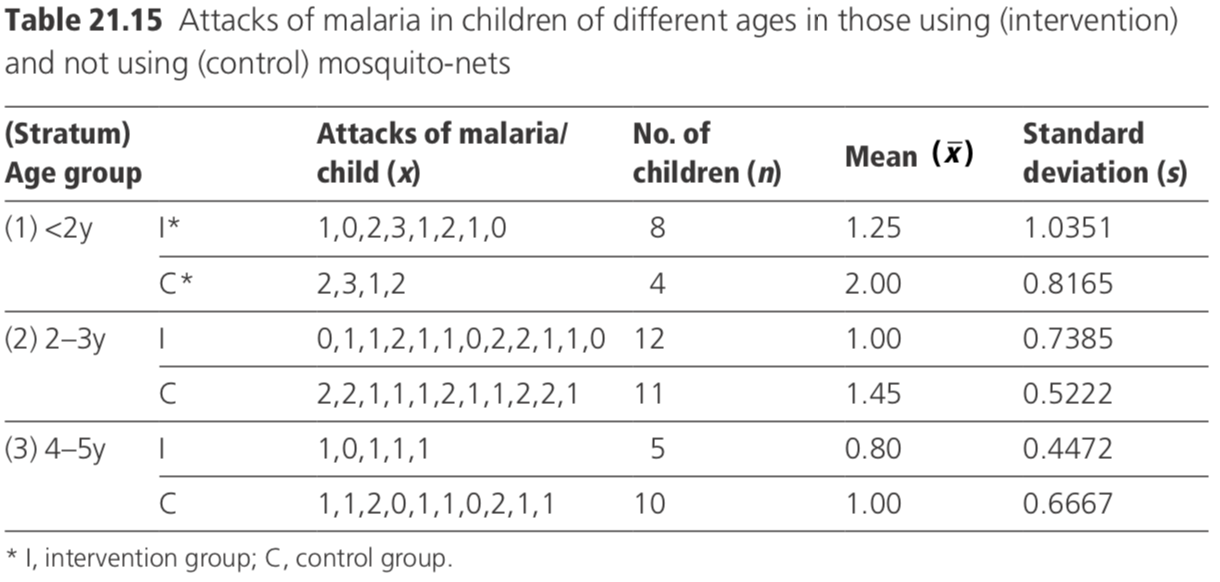
A numerical example is given in Table 21.15 where the comparison is between sub- jects using mosquito nets (intervention group) and those not using them (control group), and the outcome measure (x) is the number of episodes of malaria over a pe- riod of 1 year. In this example, age is considered as the confounding variable, and the stratification has been made by dividing the study subjects into three age groups. The size of each subgroup has been made small to simplify the computations for illustrative purposes.
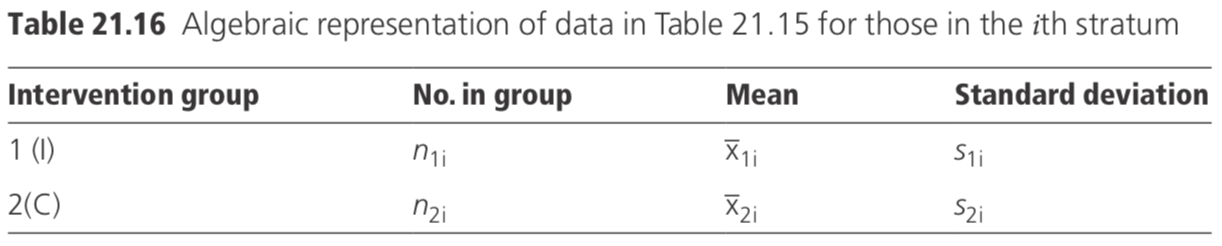
The data may be represented algebraically for those in the ith stratum, as shown in Table 21.16.
An estimate of the common difference in response between the intervention and control groups is obtained by calculating a weighted average of the differences within each stratum:
\[
d=\Sigma w_{i} d_{i} / \Sigma w_{i}
\]
where \(w_{i}=\left[n_{1 i} n_{2 i} /\left(n_{1 i}+n_{2 i}\right)\right]\)
Difference
$$
d_{i}=\overline{x}_{1}-\overline{x}_{2}
\]
Thus, in the example:
\[\begin{align} d &=\{[(−0.75)32/12]+[(−0.45)132/23]+[(−0.20)50/15]\}/\{(32/12)+(132/23)+(50/15)\} \\ &=−5.25/11.75 \\ &=−0.45. \end{align}\]
An overall test of significance is obtained by calculating a test statistic as:
\[
\Sigma w_{i} d_{i} /\left[s \sqrt{\Sigma} w_{i}\right]
\]
where \(s=√\{[∑(n_{1i}−1)s^2{1i} +∑(n_{2i}−1)s^2{2i}]/∑(n_{1i}+n_{2i}−2)\}\) , and the value of the test statistic can be compared with tables of the t-distribution with \(\sum\left(n_{1 i}+n_{2 i}-2\right)\)df.
In the example:
\[
s=\sqrt{( } 23.0265 / 44 )=0.7234
\]
The test statistic (44 df) is:
\[
-5.25[0.7234 \times \sqrt{( } 11.74) ]=-2.12
\]
The absolute value is larger than 2.02, which is the tabulated 5% value for t with 44 df. Thus, there is statistically significant evidence regarding the efficacy of intervention; the reduction in the average number of episodes of malaria is estimated as 0.45 per child per year. The 95% confidence limits on the difference are given by:
\[
\left(\sum w_{\mathrm{i}} d_{\mathrm{i}} / \Sigma w_{\mathrm{i}}\right) \pm t s / \Sigma w_{\mathrm{i}}
\]
where t is taken from tables of the t-distribution for 95% confidence limits with \(\sum\left(n_{1 i}+n_{2 i}-2\right)\)df.
Thus, the 95% confidence limits are:
\[
-0.45 \pm 2.02 /(0.723) / \sqrt{(11.74)}=0.88 \mathrm{to}-0.02 \text { episodes/year/child. }
\]
If it is thought that the intervention is likely to affect the response measured in arelative, rather than an absolute, fashion (i.e. a constant percentage reduction in the number of malaria attacks, rather than a constant absolute reduction in the number of malaria attacks), then it would be appropriate to transform the data initially by taking logarithms of the number of attacks (or, say, loge(number of attacks + 0.1) to avoid zero numbers) and to perform the calculation on the transformed values.