
2.5: Mathematical Formulations
- Page ID
- 12567

Now you've got an intuitive understanding of how the neuron integrates excitation and inhibition. We can capture this dynamic in a set of mathematical equations that can be used to simulate neurons on the computer. The first set of equations focuses on the effects of inputs to a neuron. The second set focuses on generating outputs from the neuron. We will cover a fair amount of mathematical ground here. Don't worry if you don't follow all of the details. As long as you follow conceptually what the equations are doing, you should be able to build on this understanding when you get your hands on the actual equations themselves and explore how they behave with different inputs and parameters. You will see that despite all the math, the neuron's behavior is indeed simple: the amount of excitatory input determines how excited it gets, in balance with the amount of inhibition and leak. And the resulting output signals behave pretty much as you would expect.
Computing Inputs
We begin by formalizing the "strength" by which each side of the tug-of-war pulls, and then show how that causes the \(V_{m}\) "flag" to move as a result. This provides explicit equations for the tug-of-war dynamic integration process. Then, we show how to actually compute the conductance factors in this tug-of-war equation as a function of the inputs coming into the neuron, and the synaptic weights (focusing on the excitatory inputs for now). Finally, we provide a summary equation for the tug-of-war which can tell you where the flag will end up in the end, to complement the dynamical equations which show you how it moves over time.
Neural Integration
The key idea behind these equations is that each guy in the tug-of-war pulls with a strength that is proportional to both its overall strength (conductance), and how far the "flag" (\(V_{m}\)) is away from its position (indicated by the driving potential E). Imagine that the tuggers are planted in their position, and their arms are fully contracted when the \(V_{m}\) flag gets to their position (E), and they can't re-grip the rope, such that they can't pull any more at this point. To put this idea into an equation, we can write the "force" or current that the excitatory guy exerts as:
- excitatory current:
\[I_{e}=g_{e}\left(E_{e}-V_{m}\right)\]
The excitatory current is  (I is the traditional term for an electrical current, and e again for excitation), and it is the product of the conductance
(I is the traditional term for an electrical current, and e again for excitation), and it is the product of the conductance  times how far the membrane potential is away from the excitatory driving potential. If
times how far the membrane potential is away from the excitatory driving potential. If  then the excitatory guy has "won" the tug of war, and it no longer pulls anymore, and the current goes to zero (regardless of how big the conductance might be -- anything times 0 is 0). Interestingly, this also means that the excitatory guy pulls the strongest when the \(V_{m}\) "flag" is furthest away from it -- i.e., when the neuron is at its resting potential. Thus, it is easiest to excite a neuron when it's well rested.
then the excitatory guy has "won" the tug of war, and it no longer pulls anymore, and the current goes to zero (regardless of how big the conductance might be -- anything times 0 is 0). Interestingly, this also means that the excitatory guy pulls the strongest when the \(V_{m}\) "flag" is furthest away from it -- i.e., when the neuron is at its resting potential. Thus, it is easiest to excite a neuron when it's well rested.
The same basic equation can be written for the inhibition guy, and also separately for the leak guy (which we can now reintroduce as a basic clone of the inhibition term):
- inhibitory current:
\[I_{i}=g_{i}\left(E_{i}-V_{m}\right) \]
- leak current:
\[I_{l}=g_{l}\left(E_{l}-V_{m}\right)\]
(only the subscripts are different).
Next, we can add together these three different currents to get the net current, which represents the net flow of charged ions across the neuron's membrane (through the ion channels):
- net current:
\[I_{n e t}=I_{e}+I_{i}+I_{l}=g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\]
So what good is a net current? Recall that electricity is like water, and it flows to even itself out. When water flows from a place where there is a lot of water to a place where there is less, the result is that there is less water in the first place and more in the second. The same thing happens with our currents: the flow of current changes the membrane potential (height of the water) inside the neuron:
- update of membrane potential due to net current:
\[V_{m}(t)=V_{m}(t-1)+d t_{v m} I_{n e t}\]
\[V_{m}(t)\) is the current value of \(V_{m}\), which is updated from value on the previous time step \(V_{m}(t-1)\), and the \(d t_{v m}\) is a rate constant that determines how fast the membrane potential changes -- it mainly reflects the capacitance of the neuron's membrane).
The above two equations are the essence of what we need to be able to simulate a neuron on a computer! It tells us how the membrane potential changes as a function of the inhibitory, leak and excitatory inputs -- given specific numbers for these input conductances, and a starting \(V_{m}\) value, we can then iteratively compute the new \(V_{m}\) value according to the above equations, and this will accurately reflect how a real neuron would respond to similar such inputs!
To summarize, here's a single version of the above equations that does everything:
- \(V_{m}(t)=V_{m}(t-1)+d t_{v m}\left[g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\right]\)
For those of you who noticed the issue with the minus sign above, or are curious how all of this relates to Ohm's law and the process of diffusion, please see Electrophysiology of the Neuron. If you're happy enough with where we've come, feel free to move along to finding out how we compute these input conductances, and what we then do with the \(V_{m}\) value to drive the output signal of the neuron.
Computing Input Conductances
The excitatory and inhibitory input conductances represent the total number of ion channels of each type that are currently open and thus allowing ions to flow. In real neurons, these conductances are typically measured in nanosiemens (nS), which is \(10^{-9}\) siemens (a very small number -- neurons are very tiny). Typically, neuroscientists divide these conductances into two components:
- \(\overline{g}\) ("g-bar") -- a constant value that determines the maximum conductance that would occur if every ion channel were to be open.
- \(g(t)\) -- a dynamically changing variable that indicates at the present moment, what fraction of the total number of ion channels are currently open (goes between 0 and 1).
Thus, the total conductances of interest are written as:
- excitatory conductance:
\[\overline{g}_{e} g_{e}(t)\]
- inhibitory conductance:
\[\overline{g}_{i} g_{i}(t)\]
- leak conductance:
\[\overline{g}_{l}\]
(note that because leak is a constant, it does not have a dynamically changing value, only the constant g-bar value).
This separation of terms makes it easier to compute the conductance, because all we need to focus on is computing the proportion or fraction of open ion channels of each type. This can be done by computing the average number of ion channels open at each synaptic input to the neuron:
- \(g_{e}(t)=\frac{1}{n} \sum_{i} x_{i} w_{i}\)
where \(x_{i}\) is the activity of a particular sending neuron indexed by the subscript \(i\), \(w_{i}\) is the synaptic weight strength that connects sending neuron \(i\) to the receiving neuron, and \(n\) is the total number of channels of that type (in this case, excitatory) across all synaptic inputs to the cell. As noted above, the synaptic weight determines what patterns the receiving neuron is sensitive to, and is what adapts with learning -- this equation shows how it enters mathematically into computing the total amount of excitatory conductance.
The above equation suggests that the neuron performs a very simple function to determine how much input it is getting: it just adds it all up from all of its different sources (and takes the average to compute a proportion instead of a sum -- so that this proportion is then multiplied by g_bar_e to get an actual conductance value). Each input source contributes in proportion to how active the sender is, multiplied by how much the receiving neuron cares about that information -- the synaptic weight value. We also refer to this average total input as the net input.
The same equation holds for inhibitory input conductances, which are computed in terms of the activations of inhibitory sending neurons, times the inhibitory weight values.
There are some further complexities about how we integrate inputs from different categories of input sources (i.e., projections from different source brain areas into a given receiving neuron), which we deal with in the optional subsection: Net Input Detail. But overall, this aspect of the computation is relatively simple and we can now move on to the next step, of comparing the membrane potential to the threshold and generating some output.
Equilibrium Membrane Potential
Before finishing up the final step in the detection process (generating an output), we will need to use the concept of the equilibrium membrane potential, which is the value of \(V_{m}\) that the neuron will settle into and stay at, given a fixed set of excitatory and inhibitory input conductances (if these aren't steady, then the \(V_{m}\) will likely be constantly changing as they change). This equilibrium value is interesting because it tells us more clearly how the tug-of-war process inside the neuron actually balances out in the end. Also, we will see in the next section that it is useful mathematically.
To compute the equilibrium membrane potential \(\left(V_{m}^{e q}\right)\), we can use an important mathematical technique: set the change in membrane potential (according to the iterative \(V_{m}\) updating equation from above) to 0, and then solve the equation for the value of \(V_{m}\) under this condition. In other words, if we want to find out what the equilibrium state is, we simply compute what the numbers need to be such that \(V_{m}\) is no longer changing (i.e., its rate of change is 0). Here are the mathematical steps that do this:
- iterative \(V_{m}\) update equation:
\[V_{m}(t)=V_{m}(t-1)+d t_{v m}\left[g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\right]\]
- just the change part (time constant omitted as we are looking for equilibrium):
\[\Delta V_{m}=g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\]
- set it to zero:
\[0=g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\]
- solve for \(V_{m}\):
\[V_{m}=\frac{g_{e}}{g_{e}+g_{i}+g_{l}} E_{e}+\frac{g_{i}}{g_{e}+g_{i}+g_{l}} E_{i}+\frac{g_{l}}{g_{e}+g_{i}+g_{l}} E_{l}\]
We show the math here: Equilibrium Membrane Potential Derivation.
In words, this says that the excitatory drive \(E_{e}\) contributes to the overall \(V_{m}\) as a function of the proportion of the excitatory conductance \(g_{e}\) relative to the sum of all the conductances \(\left(g_{e}+g_{i}+g_{l}\right)\). And the same for each of the others (inhibition, leak). This is just what we expect from the tug-of-war picture: if we ignore g_l, then the \(V_{m}\) "flag" is positioned as a function of the relative balance between \(g_{e}\) and \(g_{i}\) -- if they are equal, then \(\frac{g_{e}}{g_{e}+g_{i}}\) is .5 (e.g., just put a "1" in for each of the g's -- 1/2 = .5), which means that the \(V_{m}\) flag is half-way between \(E_{i}\) and \(E_{e}\). So, all this math just to rediscover what we knew already intuitively! (Actually, that is the best way to do math -- if you draw the right picture, it should tell you the answers before you do all the algebra). But we'll see that this math will come in handy next.
Here is a version with the conductance terms explicitly broken out into the "g-bar" constants and the time-varying "g(t)" parts:
- \(V_{m}=\frac{\overline{g}_{e} g_{e}(t)}{\overline{g}_{e} g_{e}(t)+\overline{g}_{i} g_{i}(t)+\overline{g}_{l}} E_{e}+\frac{\overline{g}_{i} g_{i}(t)}{\overline{g}_{e} g_{e}(t)+\overline{g}_{i} g_{i}(t)+\overline{g}_{l}} E_{i}+\frac{\overline{g}_{l}}{\overline{g}_{e} g_{i}(t)+\overline{g}_{i} g_{i}(t)+\overline{g}_{l}} E_{l}\)
For those who really like math, the equilibrium membrane potential equation can be shown to be a Bayesian Optimal Detector.
Generating Outputs
The output of the neuron can be simulated at two different levels: discrete spiking (which is how neurons actually behave biologically), or using a rate code approximation. We cover each in turn, and show how the rate code must be derived to match the behavior of the discrete spiking neuron, when averaged over time (it is important that our approximations are valid in the sense that they match the more detailed biological behavior where possible, even as they provide some simplification).
Discrete Spiking
To compute discrete action potential spiking behavior from the neural equations we have so far, we need to determine when the membrane potential gets above the firing threshold, and then emit a spike, and subsequently reset the membrane potential back down to a value, from which it can then climb back up and trigger another spike again, etc. This is actually best expressed as a kind of simple computer program:
- if (Vm > θ) then: y = 1; Vm = Vm_r; else y = 0
where y is the activation output value of the neuron, and Vm_r is the reset potential that the membrane potential is reset to after a spike is triggered. Biologically, there are special potassium (K+) channels that bring the membrane potential back down after a spike.
This simplest of spiking models is not quite sufficient to account for the detailed spiking behavior of actual cortical neurons. However, a slightly more complex model can account for actual spiking data with great accuracy (as shown by Gerstner and colleagues (Brette & Gerstner, 2005), and winning several international competitions even!). This model is known as the Adaptive Exponential or AdEx model -- click on the link to read more about it. We typically use this AdEx model when simulating discrete spiking, although the simpler model described above is also still an option. The critical feature of the AdEx model is that the effective firing threshold adapts over time, as a function of the excitation coming into the cell, and its recent firing history. The net result is a phenomenon called spike rate adaptation, where the rate of spiking tends to decrease over time for otherwise static input levels. Otherwise, however, the AdEx model is identical to the one described above.
Rate Code Approximation to Spiking
Even though actual neurons communicate via discrete spiking (action potential) events, it is often useful in our computational models to adopt a somewhat more abstract rate code approximation, where the neuron continuously outputs a single graded value (typically normalized between 0-1) that reflects the overall rate of spiking that the neuron should be exhibiting given the level of inputs it is receiving. In other words, we could count up the number of discrete spikes the neuron fires, and divide that by the amount of time we did the counting over, and this would give us an average spiking rate. Instead of having the neuron communicate this rate of spiking distributed in discrete spikes over that period of time, we can have it communicate that rate value instantly, as a graded number. Computationally, this should be more efficient, because it is compressing the amount of time required to communicate a particular spiking rate, and it also tends to reduce the overall level of noise in the network, because instead of switching between spiking and not-spiking, the neuron can continuously output a more steady rate code value.
As noted earlier, the rate code value can be thought of in biological terms as the output of a small population (e.g., 100) of neurons that are generally receiving the same inputs, and giving similar output responses -- averaging the number of spikes at any given point in time over this population of neurons is roughly equivalent to averaging over time from a single spiking neuron. As such, we can consider our simulated rate code computational neurons to correspond to a small population of actual discrete spiking neurons.
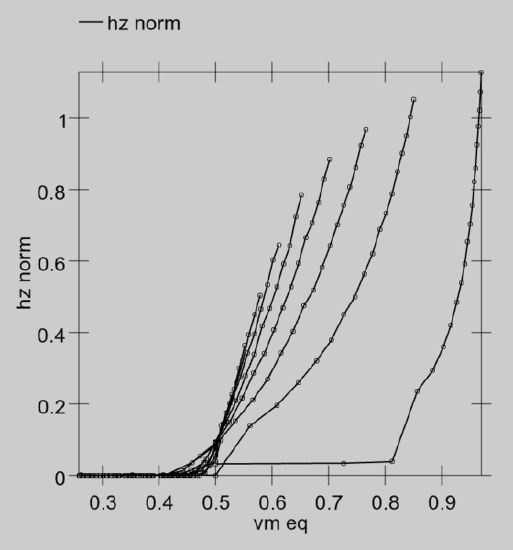
To actually compute the rate code output, we need an equation that provides a real-valued number that matches the number of spikes emitted by a spiking neuron with the same level of inputs. Interestingly, you cannot use the membrane potential \(V_{m}\) as the input to this equation -- it does not have a one-to-one relationship with spiking rate! That is, when we run our spiking model and measure the actual rate of spiking for different combinations of excitatory and inhibitory input, and then plot that against the equilibrium \(V_{m}\) value that those input values produce (without any spiking taking place), there are multiple spiking rate values for each \(V_{m}\) value -- you cannot predict the correct firing rate value knowing only the \(V_{m}\) (Figure 2.5).
{kind=link}
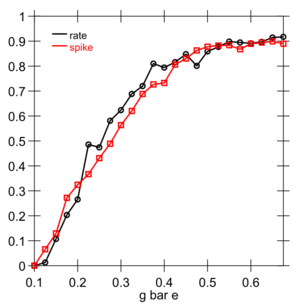
Instead, it turns out that the excitatory net input \(g_{e}\) enables a good prediction of actual spiking rate, when it is compared to an appropriate threshold value (Figure 2.6). For the membrane potential, we know that \(V_{m}\) is compared to the threshold \(\theta\) to determine when output occurs. What is the appropriate threshold to use for the excitatory net input? We need to somehow convert \(\theta\) into a \(g_{e}^{\Theta}\) value -- a threshold in excitatory input terms. Here, we can leverage the equilibrium membrane potential equation, derived above. We can use this equation to solve for the level of excitatory input conductance that would put the equilibrium membrane potential right at the firing threshold \(\theta\):
{kind=link}
- equilibrium \(V_{m}\) at threshold:
\[\Theta=\frac{g_{e}^{\Theta} E_{e}+g_{i} E_{i}+g_{l} E_{l}}{g_{e}^{\Theta}+g_{i}+g_{l}}\]
- solved for g_{e}^{\Theta}:
\[g_{e}^{\Theta}=\frac{g_{i}\left(E_{i}-\Theta\right)+g_{l}\left(E_{l}-\Theta\right)}{\Theta-E_{e}}\]
(see g_{e}^{\Theta} derivation for the algebra to derive this solution),
Now, we can say that our rate coded output activation value will be some function of the difference between the excitatory net input g_{e} and this threshold value:
- \(y=f\left(g_{e}-g_{e}^{\Theta}\right)\)
And all we need to do is figure out what this function f() should look like.
There are three important properties that this function should have:
- threshold -- it should be 0 (or close to it) when \(g_{e}\) is less than its threshold value (neurons should not respond when below threshold).
- saturation -- when \(g_{e}\) gets very strong relative to the threshold, the neuron cannot actually keep firing at increasingly high rates -- there is an upper limit to how fast it can spike (typically around 100-200 Hz or spikes per second). Thus, our rate code function also needs to exhibit this leveling-off or saturation at the high end.
- smoothness -- there shouldn't be any abrupt transitions (sharp edges) to the function, so that the neuron's behavior is smooth and continuous.
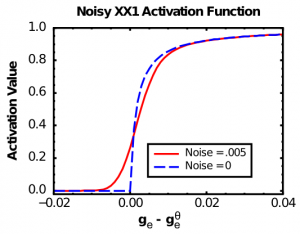
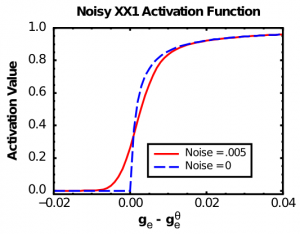
The X-over-X-plus-1 (XX1) function (Figure 2.7, Noise=0 case, also known as the Michaelis-Mentin kinetics function -- Wikipedia link) exhibits the first two of these properties:
{kind=link}
- \(f_{x x 1}(x)=\frac{x}{x+1}\)
where x is the positive portion of  , with an extra gain factor
, with an extra gain factor  , which just multiplies everything:
, which just multiplies everything:
- \(x=\gamma\left[g_{e}-g_{e}^{\Theta}\right]_{+}\)
So the full equation is:
- \(y=\frac{\gamma\left[g_{e}-g_{e}^{\Theta}\right]_{+}}{\gamma\left[g_{e}-g_{e}^{\Theta}\right]_{+}+1}\)
Which can also be written as:
- \(y=\frac{1}{\left(1+\frac{1}{\gamma\left[g_{c}-g_{e}^{\ominus}\right]_{+}}\right)}\)
As you can see in Figure 2.7 (Noise=0), the basic XX1 function is not smooth at the point of the threshold. To remedy this problem, we convolve the XX1 function with normally-distributed (gaussian) noise, which smooths it out as shown in the Noise=0.005 case in Figure 2.7. Convolving amounts to adding to each point in the function some contribution from its nearby neighbors, weighted by the gaussian (bell-shaped) curve. It is what photo editing programs do when they do "smoothing" or "blurring" on an image. In the software, we perform this convolution operation and then store the results in a lookup table of values, to make the computation very fast. Biologically, this convolution process reflects the fact that neurons experience a large amount of noise (random fluctuations in the inputs and membrane potential), so that even if they are slightly below the firing threshold, a random fluctuation can sometimes push it over threshold and generate a spike. Thus, the spiking rate around the threshold is smooth, not sharp as in the plain XX1 function.
For completeness sake, and strictly for the mathematically inclined, here is the equation for the convolution operation:
- \(y^{*}(x)=\int_{-\infty}^{\infty} \frac{1}{\sqrt{2 \pi} \sigma} e^{-z^{2} /\left(2 \sigma^{2}\right)} y(z-x) d z\)
where y(z-x) is the XX1 function applied to the z-x input instead of just x. In practice, a finite kernel of width \(3 \sigma\) on either side of x is used in the numerical convolution.
After convolution, the XX1 function (Figure 2.7) approximates the average firing rate of many neuronal models with discrete spiking, including AdEx. A mathematical explanation is here: Frequency-Current Curve.
Restoring Iterative Dynamics in the Activation
There is just one last problem with the equations as written above. They don't evolve over time in a graded fashion. In contrast, the \(V_{m}\) value does evolve in a graded fashion by virtue of being iteratively computed, where it incrementally approaches the equilibrium value over a number of time steps of updating. Instead the activation produced by the above equations goes directly to its equilibrium value very quickly, because it is calculated based on excitatory conductance and does not take into account the sluggishness with which changes in conductance lead to changes in membrane potentials (due to capacitance). As discussed in the Introduction, graded processing is very important, and we can see this very directly in this case, because the above equations do not work very well in many cases because they lack this gradual evolution over time.
To introduce graded iterative dynamics into the activation function, we just use the activation value (\(y^{*}(x)\)) from the above equation as a driving force to an iterative temporally-extended update equation:
\[y(t)=y(t-1)+d t_{v m}\left(y^{*}(x)-y(t-1)\right)\]
This causes the actual final rate code activation output at the current time t, y(t) to iteratively approach the driving value given by \(y^{*}(x)\), with the same time constant \(d t_{v m}\) that is used in updating the membrane potential. In practice this works extremely well, better than any prior activation function used with Leabra.
| Parameter | Bio Val |
Norm Val |
Parameter |
Bio Val | Norm Val | |
|---|---|---|---|---|---|---|
|
Time |
0.001 sec | 1 ms | Voltage | 0.1 V or 100 mV | -100..100 mV = 0..2 dV | |
| Current | \(1 \times 10^{-8}\) A | 10 nA | Conductance | 1x10^{-9}S | 1 nS | |
| Capacitance | \(1 \times 10^{-12}\) F | 1 pF | C (memb capacitance) | 281 pF | 1/C = .355 = dt.vm | |
| \(g_{l}\) (leak) | 10 nS | 0.1 | \(g_{i}\) (inhibition) | 100 nS | 1 | |
| \(g_{e}\) (excitation) | 100 nS | 1 | e_rev_l (leak) and Vm_r | -70 mV | 0.3 | |
|
e_rev_i (inhibition) |
-75 mV | 0.25 | e_rev_e (excitation) | 0 mV |
1 |
|
| \(\theta\) (act.thr, \(\mathbf{V}_{\mathbf{T}}\) in AdEx) | -50 mV | 0.5 | spike.spk_thr (exp cutoff in AdEx) | 20 mV | 1.2 | |
| spike.exp_slope (\(\Delta_{\mathbf{T}}\) in AdEx) | 2 mV | 0.02 | adapt.dt_time (\(\tau_{W}\) in AdEx) | 144 ms | dt = 0.007 | |
| adapt.vm_gain (a in AdEx) | 4 nS | 0.04 | adapt.spk_gain (b in AdEx) | 0.0805 nA | 0.00805 |
Table \(2.1\): The parameters used in our simulations are normalized using the above conversion factors so that the typical values that arise in a simulation fall within the 0.1 normalized range. For example, the membrane potential is represented in the range between 0 and 2 where 0 corresponds to -100 mV and 2 corresponds to +100 mV and 1 is thus 0 mV (and most membrane potential values stay within 0-1 in this scale). The biological values given are the default values for the AdEx model. Other biological values can be input using the BioParams button on the LeabraUnitSpec, which automatically converts them to normalized values.
Table \(2.1\) shows the normalized values of the parameters used in our simulations. We use these normalized values instead of the normal biological parameters so that everything fits naturally within a 0..1 range, thereby simplifying many practical aspects of working with the simulations.
The final equations used to update the neuron, in computational order, are shown here, with all variables that change over time indicated as a function of (t):
1. Compute the excitatory input conductance (inhibition would be similar, but we'll discuss this more in the next chapter, so we'll omit it here):
- \(g_{e}(t)=\frac{1}{n} \sum_{i} x_{i}(t) w_{i}\)
2. Update the membrane potential one time step at a time, as a function of input conductances (separating conductances into dynamic and constant "g-bar" parts):
- \(V_{m}(t)=V_{m}(t-1)+d t_{v m}\left[\overline{g}_{e} g_{e}(t)\left(E_{e}-V_{m}\right)+\overline{g}_{i} g_{i}(t)\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\right]\)
3a. For discrete spiking, compare membrane potential to threshold and trigger a spike and reset Vm if above threshold:
- if (Vm(t) > θ) then: y(t) = 1; Vm(t) = Vm_r; else y(t) = 0
3b. For rate code approximation, compute output activation as NXX1 function of g_e and Vm:
- \(y^{*}(x)=f_{N X X 1}\left(g_{e}^{*}(t)\right) \approx \frac{1}{\left(1+\frac{1}{\gamma\left[g_{e}-g_{e}^{\Theta}\right]_{+}}\right)}\) (convolution with noise not shown)
- \(y(t)=y(t-1)+d t_{v m}\left(y^{*}(x)-y(t-1)\right)\) (restoring iterative dynamics based on time constant of membrane potential changes)