
9.5: Latent Semantics in Word Co-Occurrence
- Page ID
- 12619

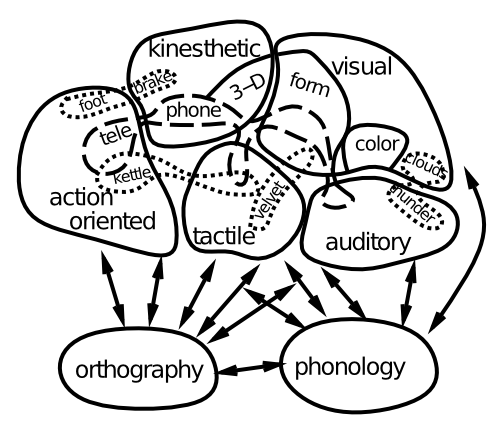
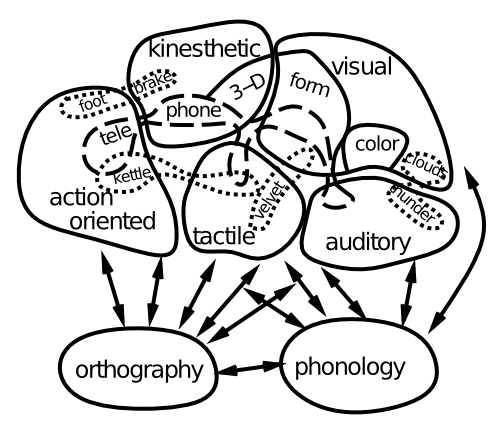
Completing our more in-depth tour of the major pathways in the triangle model of reading, we now turn to the issue of semantics. What is the nature of the semantic representations shown at the top of Figure 9.6? An increasing body of data supports the idea shown in Figure 9.9, where the meaning of concrete words is encoded by patterns of activity within domain-specific brain areas that process sensory and motor information. Thus, semantics is distributed throughout a wide swath of the brain, and it is fundamentally embodied and grounded in the sensory-motor primitives that we first acquire in life. Thus, the single "semantics" area shown in the triangle model is a major simplification relative to the actual widely distributed nature of semantic meaning in the brain.
{kind=link}
{kind=link}
However, there is also increasing evidence that the anterior tip or "pole" of the temporal lobe plays a particularly important role in representing semantic information, perhaps most importantly for more abstract words that lack a strong sensory or motor correlate. One theory is that this area acts as a central "hub" for coordinating the otherwise distributed semantic information (Patterson, Nestor, & Rogers, 2007).
How do we learn the meanings of these more abstract words in the first place? Unlike the more concrete words shown in Figure 9.9, the meanings of more abstract words cannot be so easily pushed off to sensory and motor areas. One compelling idea here is that words obtain their meaning in part from the company they keep -- the statistics of word co-occurrence across the large volume of verbal input that we are exposed to can actually provide clues as to what different words mean. One successful approach to capturing this idea in a functioning model is called Latent Semantic Analysis (LSA) -- see http://lsa.colorado.edu for full details and access to this model.
LSA works by recording the statistics of how often words co-occur with each other within semantically-relevant chunks of text, typically paragraphs. However, these surface statistics themselves are not sufficient, because for example synonyms of words occur together relatively rarely, compared to how closely related they should be. And in general, there is a lot of variability in word choice and idiosyncrasies of word choices that are reflected in these detailed statistics. The key step that LSA takes in dealing with this problem is to apply a dimensionality reduction technique called Singular Value Decomposition (SVD), which is closely related to Principal Components Analysis (PCA), which in turn is closely related to the Hebbian self-organizing learning that our neural network models perform.
The key result of this SVD/PCA/Hebbian process is to extract the strongest groupings or clusters of words that co-occur together, in a way that integrates over many partially-overlapping subsets of word groups. Thus, even though synonyms do not tend to occur with each other, they do co-occur with many of the same other sets of words, and this whole group of words represents a strong statistical grouping that will be pulled out by the dimensionality reduction / Hebbian self-organizing learning process.
This process is exactly the same as what we saw with the V1 receptive field model in the Perception Chapter. In that model, Hebbian learning extracted the statistical regularity of oriented edges from a set of natural images. Any given image typically contains a noisy, partial version of an oriented edge, with perhaps several pixels occluded or blurry or otherwise distorted. However, as the self-organizing learning process integrates over many such inputs, these idiosyncrasies wash away, and the strongest statistical groupings of features emerge as oriented edges.
Unlike the V1 model, however, the individual statistical clusters that emerge from the LSA model (including our Hebbian version of it) do not have any clear interpretation equivalent to "oriented edges". As you'll see in the exploration, you can typically make some sense of small subsets of the words, but no obvious overall meaning elements are apparent. But this is not a problem -- what really matters is that the overall distributed pattern of activity across the semantic layer appropriately captures the meanings of words. And indeed this turns out to be the case.
Exploration
- Open Semantics for the sem.proj exploration of semantic learning of word co-occurrences. The model here was trained on an early draft of the first edition of this textbook, and thus has relatively specialized knowledge, hopefully much of which is now shared by you the reader.